
Copyright 2001-2014 (c) Synthetic Reality Co.
Synthetic Reality: |
| Home Company Store Donations Contact Us |
Games: |
| Well of Souls Arcadia: > Empyrion > synChess > synJet > synPool Warpath 97 Warpath Classic NetSpades MIX Game Server |
Demos: |
| Rocket Club synVertigo synWater synBirds synVista Galaxy Simulator |
Community: |
| Forum About Us FAQ News CASH-CAM Friends |
Money: |
| Donations |
This program is FREE, not shareware. Just enjoy it.
What Is speechLab?
You know those 'text to speech' programs that take a written sentence and then speak it aloud, sounding a bit like a drunk Norwegian on crack? Well, I wanted to throw my own hat into that ring, but mainly focussing on the ability to edit the actual phonemes used, so that you can make custom voice sets for yourself, your friends, Darth Vader, etc. My supposed useful purpose is to add a feature to my chat rooms where the synthetic voice has a bit more personality than your usual TTS system.
TTS (Text to speech) has evolved a lot in recent years. As personal computers have grown more powerful and memory has been less of a constraint, developers have been unleashed to use complex mathematics to dynamically synthesize ever more drunken Norwegians. (By the way, no offense intended to Norge.. I'm 1/4 Norwegian myself!) Anyway, speechLab isn't like that. It uses technology which is 40 years old already!
Running the Program
Well, just unzip the executable and run it. It comes with a couple sub-folders you will want to keep inside the program's folder. You've done all this before. Please Note: speechLab REQUIRES DirectX, as well as a full-duplex sound card. Cheaper sound cards may not be compatible with the program. Microphone setup is between you and Windows.
| speechLab Fun With Voice, Real and Imagined | speechLab.zip |
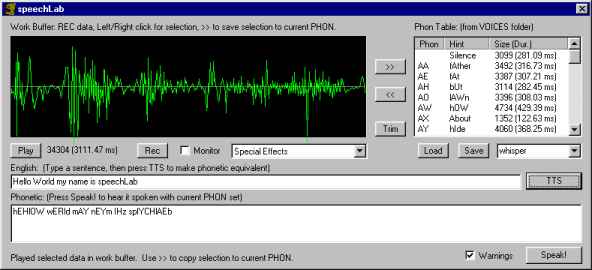
It is a dialog-based MFC app written in VC++ 4.2b It starts up with a PHON table pre-loaded, so you can just enter an English sentence into the ENGLISH text box, and then press TTS to hear it spoken with that PHON table. The phonetic description of the sentence will be left in the PHONETIC box, and pressing the SPEAK! button will re-speak the current phonetic string. (You can type in the PHONs manually as well, if you like)
In the upper right is the PHON table. Each PHON is described with a one or two letter name, a 'hint' as to what part of the word it represents, and how large the current sample is for that PHON. Click on a PHON on the list to hear what it sounds like. Your GOAL is to make a new PHON list which sounds good or funny (but can still be understood). Or klingon...
In the upper left is the WORK BUFFER. You'll need a microphone to have fun with this program. When you press the RECord buttton, up to 4 seconds of speech are recorded into the WORK BUFFER. You then use the left and right mouse buttons to select a portion of that recording. You're trying to find just the little bit with the sound you want.
For example, say you are trying to make a new PHON for "AA." The hint is "fAther." So, you push the RECord button and speech "My FATHER is cool!" When the recording finishes, you see the sound samples like a little oscilloscope screen. LEFT click in the scope to set the START of the selection, then RIGHT click somewhere to set the END of the selection. Press the PLAY button and hear just the selected (bright green) data.
First you might try to isolate the whole word "Father." Once you do that you can push the CLIP button to get rid of everything else. This has the advantage of letting the scope 'zoom in on' a smaller number of speech samples, so you can more accurately find the start and end of the "AHHH" sound in the middle of "Father" with as little "FFF" or "THHHH" as possible.
So, this is the part where you are having fun, right? Once you have isolated the AA sound, press the [>>] button to save it in the PHON Table. (Be sure to click on AA in the phon table first. [>>] copies the selected samples from the work buffer to the currently selected PHON entry. So don't accidentally blow away your hard-fought TH PHON by accident!
Anyway, repeat until you have all 42 PHONs defined, and you're ready to start speaking in a new voice! Share your PHON tables with friends (be sure to SAVE your work now and then, of course). PHON tables are stored as *.voc files in speechLab's VOICES folder.
Here is a recap of all the stuff you see on the screen:
- WORK Buffer.. oscilloscope display of current samples. You can LEFT click to set start of selection and RIGHT click to set end of selection. The selected samples will be bright green. Only the selected samples are used when you push PLAY, [>>], or CLIP.
- PHON Table... current list of PHON data. Used when you push the SPEAK! button. Use the SAVE and LOAD buttons to manage different PHON tables. The combo box beneath the list will show you what is available. But selecting something from the list just picks the name. You have to push LOAD to actually load the file. (this way you can copy tables on top of each other easily)
- [>>] Button. This copies the selected samples from the Work Buffer into the current PHON table entry (if one is selected). The old PHON table entry is lost, replaced by the new samples.
- [<<] Button. This goes the other way, copying PHON table entry to the Work Buffer. Completely replacing whatever was in the work buffer. You would do this to pull an existing PHON out for a little editing (after which you would use [>>] to put back the changed version.
- [CLIP] Button. This removes all but the selected data from the Work Buffer. It's useful for zooming in slowly on the part of the recording you're interested in keeping.
- [PLAY] Button. This plays the currently selected samples in the work buffer
- [REC] Button. This starts (or stops) a new recording (microphone samples are recorded to the Work buffer, replacing anything which might have been there before). You can stop it manually, but the recording will stop automatically after four seconds. The microphone is auto-level-sensing. So it only records while you are talking.
- [MONITOR] Checkbox. You probably want to leave this un-checked to avoide feedback. I'm just showing off that I can record and play at the same time, including the merging of several sound streams into a single stream sent to the speaker.
- [Special Effects] Combo box. This is where I stick special commands. As I write this the only one is the ability to recall the most recent recording, in its entirety (even after you have CLIPped it).
- [LOAD] button. Loads the PHONs from the VOICES folder file whose name is in the top of the combo box. (don't add the ".voc" to the name. i do that for you)
- [SAVE] button. Saves the current PHON Table to the Voices folder, using the file whose name is in the top of the combo box.
- [FILENAME] ComboBox. Shows the name of the currently selected PHON file (combo drop-down shows all ".voc" files in your VOICES folder. No actual loading or saving happens until you press the LOAD or SAVE button.
- [ENGLISH] text box. where you type your english sentence.
- [TTS] Button. Translate the english sentence into its phonetic equivalent, using the Navy Rules.
- [PHONETIC] text box. Where the translated phonemes are stored after you push the [TTS] button.
- [SPEAK!] button. Speak aloud the current phonetic text, if any.
- [Warnings] Checkbox. Most actions bring up a warning dialog which both protects you from loss of data, and acts as documentation for the function in question. Once you are a pro, you can use this checkbox to turn most of those warnings off.
- [HELP TEXT]. The bottom left line of text tries to guess what you need to know next.
Again, this is just for fun. No wagering please.
The Math
I tend to have a math section in all these demo pages, but really this one isn't much about math. Sure I do some vaguely interesting scaling in time and amplitude. And I might add some FFT stuff just to get some more math into it. But really this is mostly about:
- Recording and Playing Sound samples (all done at 11,025 samples per second. 16-bit mono samples).
- Simple editing of same.
- Maintenance of the PHON table database, and storing it to disk
- Translating English to Phonetics, using the Naval Research Laboratory Rules (developed in what, the 60s? the 70s?)
So, even though it's the recording and playback which is the most challenging part of the program to code, I guess it's that last bit which is the most interesting (and also why this is doomed to not be a state-of-the-art TTS system.) I should point to some URLs here as a study guide, but just do a web search (www.google.com) on "Speech Synthesis", "Text to Speech", "English to Phoneme", that sort of thing. You'll see the Naval Research Lab mentioned a lot. I first read about it in Byte magazine a million lifetimes ago, but lost track of the article. A more recent web search located the rules again (with special thanks to John A. Wasser for a very neatly documented pile of rules.)
So, what's a rule? Well, first, what's a phoneme? (or a PHON, as I call it here).
Say "Hello."
Now, say it again, as slowly as you can. What you actually said was "EH UH UL OH." Four separate little sounds about 100 msecs long each. We'll call those 'phonemes' They are like atoms. They are a teensy little unit that language utterances can be broken into. (I just mean the SOUNDS of spoken language, not the MEANINGS). The actual sounds used vary with the language, and there are generally thousands of unique sounds, but lots of them are really very similar. In speechLab, English is broken down into about 40 of these sounds, which I call PHONs.
The naval research rules give us a way to turn an arbitrary english phrase into a sequence of these PHONs. Unfortunately, the result is not really very easy to understand, so it doesn't sound like a normal person. The point is that it CAN be understood.
But just to give an example, consider the words "Cat" and "Ceiling." In one case the letter 'c' is pronounced as a K, while in the other as an 's.' The navy rules look at the letters to the left and the right of the 'c' and determine which PHON might make more sense. But as anyone learning english for the first time can tell you, English pronunciation rules suck! We have incorporated so many words (that's another problem, too many words!) from so many different languages, that the pronunciation is often unpredictable... The classic example: cough, rough, bough, through, though, slough, etc.
So, while the Navy rules don't do a perfect job, they do a darn GOOD job for having so few rules to begin with.
COPYRIGHT
speechLab is the property of Synthetic Reality and all rights are reserved. If we can figure out a way to convince people to pay for this, you can be sure we'll give it a try. But for now it is expressly intended to provide a moment of joy for the speech geeks in the audience!
Thanks for your feedback in advance!
Dan Samuel
Synthetic Reality Co.